
In the 2015 US Retail Fraud Survey, retailers across the country identified analytics and monitoring as the number-one area of need. With the average US retailer experiencing shrinkage at a level comprising 1.3 percent of total sales (resulting in an annual $60 billion loss industry-wide) at that time, it’s no wonder that businesses began to look to analytics and big data to help limit this loss.
Given this increased focus on analytics, for the 2016 Retail Industry Leaders Association (RILA) Asset Protection Conference, 7-Eleven partnered with the University of Texas Master of Science in Business Analytics (MSBA) program to better understand the relationship between inventory loss and fraudulent activity.
Over the course of four months, the student group worked closely with asset protection program experts at 7-Eleven to better understand the intricacies of the business model, formulate hypotheses about store-level fraudulent activity, and evaluate findings from the data analysis to make business recommendations.
Exploratory Research into the Asset Protection Program
First, we knew we needed to gain a solid understanding of 7-Eleven’s business before we could use analytics to identify fraudulent activity. After several visits to different 7-Eleven stores to observe inventory audits and perform cycle counts, we discussed the data available to us for analysis with our mentors at 7-Eleven.
 7-Eleven currently uses sales reducing activity (SRA) levels as an identifier for fraud. SRA covers a wide range of store activities that are a part of the standard business operations for a 7-Eleven store, including aborts, item voids, price overrides, transactions with discounts, and so forth. While many of the occurrences of these SRA are not tied to fraudulent activity, a store with abnormally high levels of SRA indicates that certain transactions are being misused and abused at that store.
7-Eleven currently uses sales reducing activity (SRA) levels as an identifier for fraud. SRA covers a wide range of store activities that are a part of the standard business operations for a 7-Eleven store, including aborts, item voids, price overrides, transactions with discounts, and so forth. While many of the occurrences of these SRA are not tied to fraudulent activity, a store with abnormally high levels of SRA indicates that certain transactions are being misused and abused at that store.
Next, we wanted to collaborate with our mentors at 7-Eleven to come up with hypotheses about how different fraudulent activities could be reflected in the data. Besides SRA, what other metrics could we look at to identify fraud?
Through our discussions, we determined that inventory variation and cash purchases could both be used as fraud indicators. Inventory variation is the periodic difference between the book value of inventory and the actual value of inventory in the store. Inventory shortages (negative inventory variations) can be due to fraud. Cash purchases are inventory purchases by a 7-Eleven franchise on products outside of the standard 7-Eleven assortment. They allow a franchise store to personalize its inventory assortment to its local market.
For example, a 7-Eleven store located near the University of Texas at Austin campus may decide to stock University of Texas sports apparel. Because of this unique business model, cash purchases can be used to commit fraud. For example, a franchisee may leave gross profit off the books by underreporting or not reporting at all certain cash purchases. Additionally, because franchisees bear the full burden of inventory shortages, they can commit fraud by covering up inventory shortages with misreported cash purchases. However, it is important to note that similar to SRA, not all instances of inventory variation and cash purchases are a result of fraud.
instances of inventory variation and cash purchases are a result of fraud.
Approach
Because not all SRA, inventory variation, and cash purchases are tied to fraudulent activity, we needed to take a methodical approach to untangle the complexities of the problem and better understand how all of these factors interrelate. Most importantly, we wanted to ensure that the results of our analysis made sense within the context of the business.
Specifically, we wanted to filter and hone in on the instances of inventory variation that are caused by fraudulent SRA and the associated cash purchases used to cover them up. To do this, we transformed and merged multiple data sets from 7-Eleven that contained two years of financial and SRA data for stores located in the Texas market.
Financial data included store-level sales, profits, inventory levels, cash purchases, and so forth on a monthly basis. SRA data included store-level counts of sales reducing activities, the dollar values associated with these transactions, and the percent of total transactions for each SRA. In total, this amounted to over two million data points. Using techniques such as LASSO and logistic regression in R and Python, we explored the relationship between SRA, inventory variation, and cash purchases and their effects on sales and profitability (see figure 1). Then, we visualized our results using Tableau.
Findings
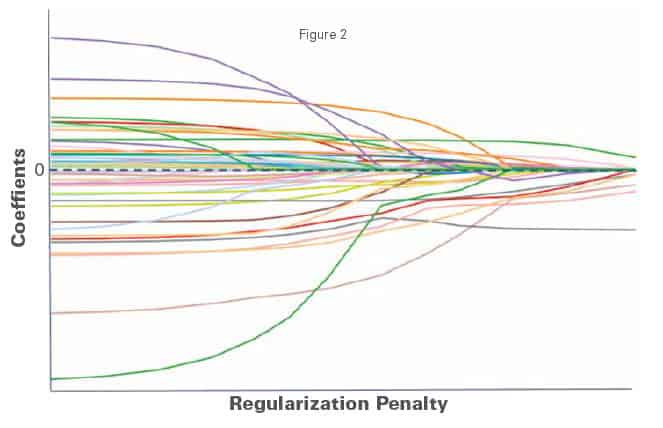
First, we wanted to quantify the financial impact of fraudulent activity on the profitability of 7-Eleven stores. Next, we wanted to untangle the relationship between SRA and inventory variation. Specifically, we aimed to separate the seventy different SRA measures into significant and not significant factors in terms of their correlation with inventory shortage. Using a LASSO (least absolute shrinkage and selection operator) regression, we were able to eliminate factors whose coefficients quickly converged to zero. Out of the original seventy SRA measures, ten were found to be the most important to focus on for identifying fraudulent activity (see figure 2).
After looking at the relationship between SRA and inventory variation, we wanted to understand how all of these risk metrics relate to the sales of a 7-Eleven store. In our attempts to model the sales of a 7-Eleven store, we wanted to be sure to include traditional drivers of sales. Based on our exploratory research, we divided these drivers into two categories: store-specific and month-specific characteristics.
Store-specific characteristics included things like location, age, and size of the store, as well as whether the store sold gasoline and/or alcohol. For example, take two stores that are identical in every way except one is located at a busy intersection and the other is located in a more remote area. We would expect the sales of the store at the busy intersection to be higher than that of the store in the remote area. Month-specific characteristics included things like seasonality of the business, the economy, weather, and company-wide promotions. For example, we would expect to see the sales of stores to be higher in the months in which the economy is doing well and consumers are spending more.
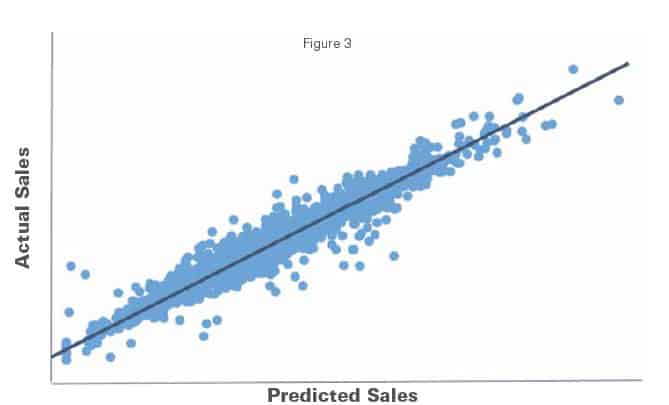
To include all of these sales drivers in our regression model in an efficient way, we used a lagged sales variable to account for store-specific characteristics and time dummy variables to account for month-specific characteristics. From our regression modeling exercise, we were able not only to confirm our hypothesis that inventory variation, cash purchases, and SRA all have negative effects on the overall sales of a 7-Eleven store, but also to quantify exactly how much these risk metrics are correlated with a drop in sales. We felt confident in our findings since the model was able to predict the sales of a 7-Eleven store on a monthly basis with a 3 percent margin of error (see figure 3).
Finally, we shifted our focus to how we could use the analysis to help make business recommendations. Given the fact that 7-Eleven spends a significant amount of time, effort, and money on detecting fraud and taking the appropriate next steps with its asset protection teams, it is important to optimize the asset protection program investment. One way to do this is by prioritizing the fraudulent stores that the 7-Eleven AP teams should pursue.
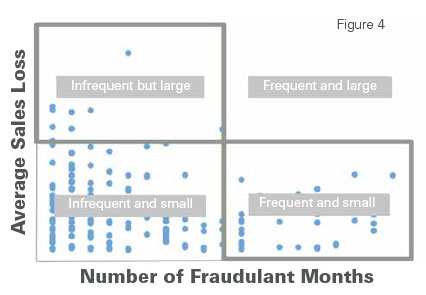
We looked at fraudulent stores in two aspects—the number of months they were believed to have committed fraud and the average associated sales loss when they did commit fraud (see figure 4). When we do this, we see that stores fall into one of three quadrants:
- Stores that committed fraud infrequently resulting in large sales losses;
- Stores that committed fraud infrequently in small amounts; and
- Stores that committed fraud frequently in small amounts.
No stores fell in the quadrant that committed fraud frequently at large levels of sales loss. This exercise clearly shows that 7-Eleven should focus its asset protection program investment on the stores that fall into the first and third quadrants, stores that commit “infrequent but large” fraud and stores that commit “frequent but small” fraud.
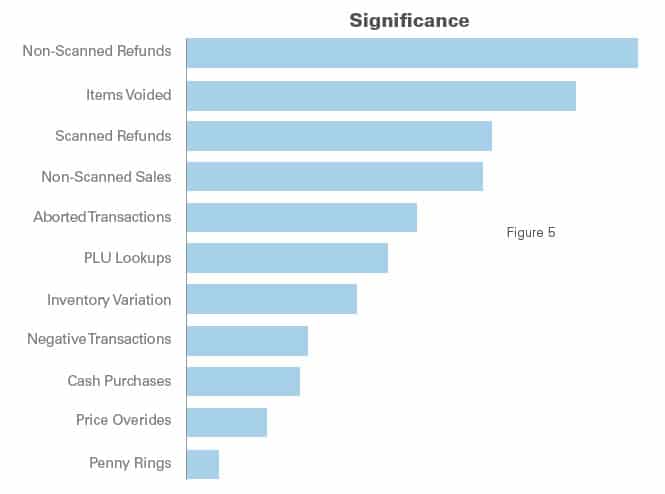
However, in this case, we are classifying fraudulent stores after the fact. To predict which stores are likely to commit particularly flagrant fraud before they do it, we created a logistic regression model that finds the difference between the stores in the quadrants of interest and the stores not in the quadrants of interest. Using this model, we were able to identify the top predictors for our priority fraudulent stores. These predictors include, unsurprisingly, inventory variation, cash purchases, and a subset of SRA measures. Figure 5 shows these predictors ranked in order of their ability to predict whether a store is likely to partake in particularly costly fraud.
Check out the full article, Predictive Data Analytics, to review the study’s conclusions and learn more about RILA’s Student Mentor program.